Garrett Bingham

About Me
I am a research scientist at Google DeepMind, where I work on large language models (LLMs) and automated machine learning (AutoML). I have published at NeurIPS, AAAI, Neural Networks, GECCO, ACL, and IEEE Big Data.
Research
Optimizing Neural Networks through Activation Function Discovery and Automatic Weight Initialization
Garrett Bingham
PhD Dissertation
Automated machine learning (AutoML) methods improve upon existing models by optimizing various aspects of their design. While present methods focus on hyperparameters and neural network topologies, other aspects of neural network design can be optimized as well. To further the state of the art in AutoML, this dissertation introduces techniques for discovering more powerful activation functions and establishing more robust weight initialization for neural networks. These contributions improve performance, but also provide new perspectives on neural network optimization. First, the dissertation demonstrates that discovering solutions specialized to specific architectures and tasks gives better performance than reusing general approaches. Second, it shows that jointly optimizing different components of neural networks is synergistic, and results in better performance than optimizing individual components alone. Third, it demonstrates that learned representations are easier to optimize than hard-coded ones, creating further opportunities for AutoML. The dissertation thus makes concrete progress towards fully automatic machine learning in the future.
Efficient Activation Function Optimization through Surrogate Modeling
Garrett Bingham and Risto Miikkulainen
NeurIPS 2023
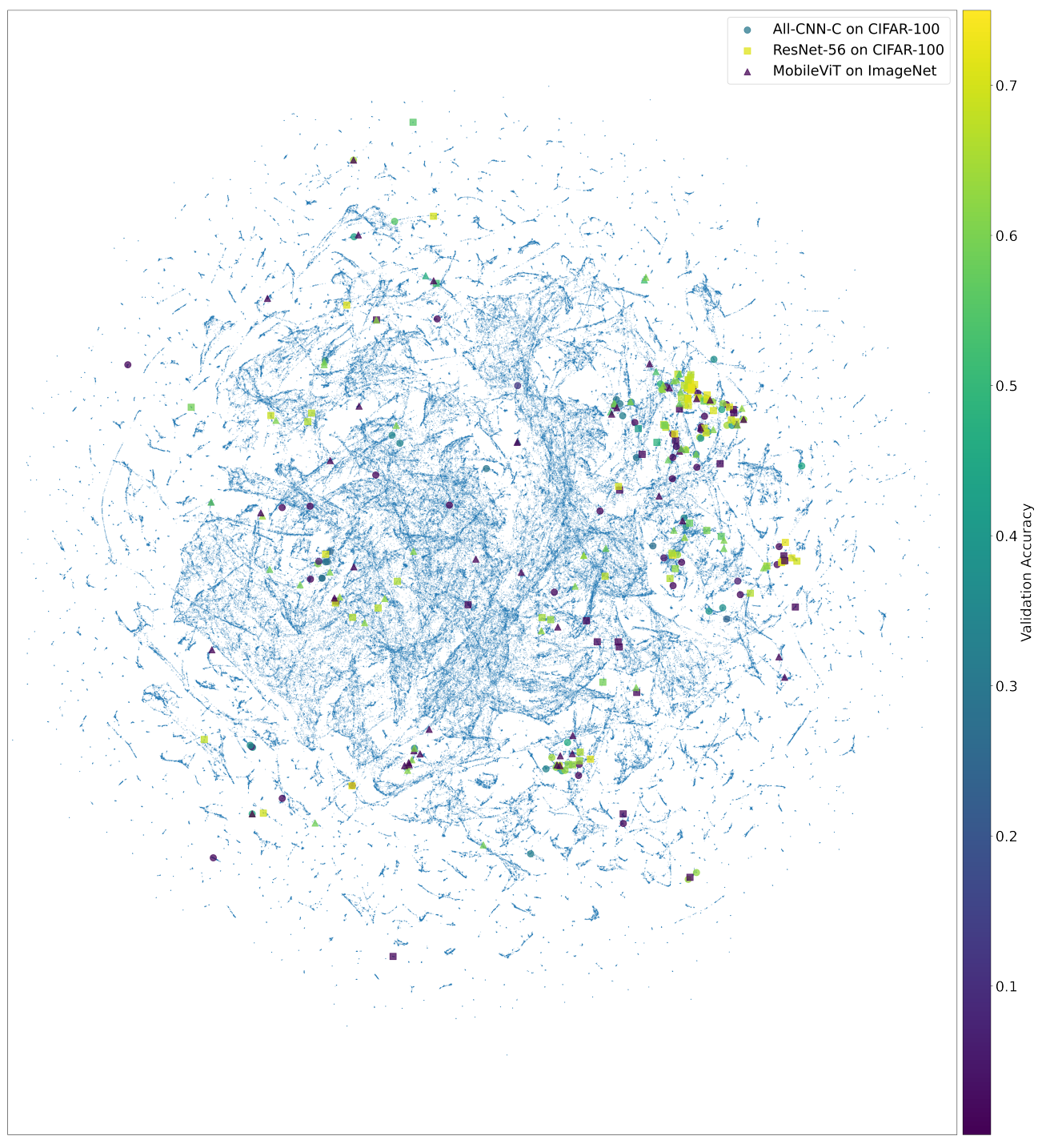
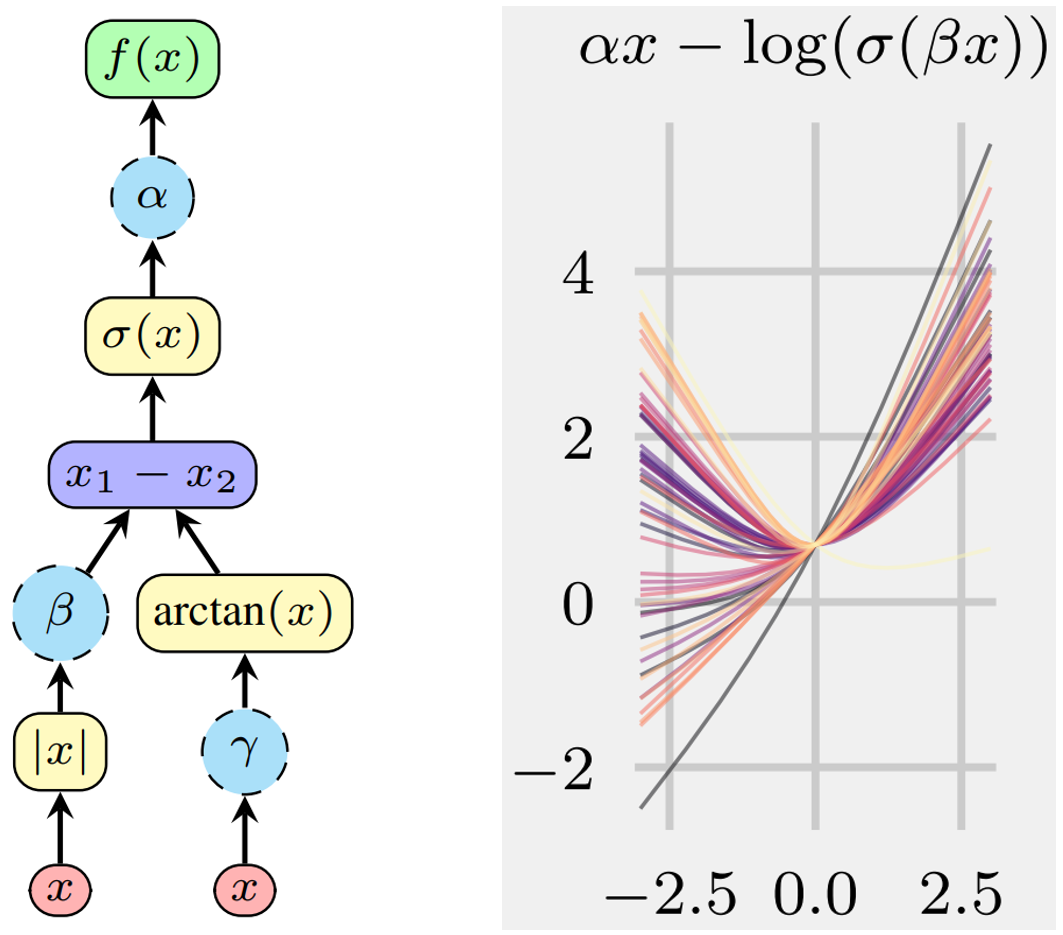
Carefully designed activation functions can improve the performance of neural networks in many machine learning tasks. However, it is difficult for humans to construct optimal activation functions, and current activation function search algorithms are prohibitively expensive. This paper aims to improve the state of the art through three steps: First, the benchmark datasets Act-Bench-CNN, Act-Bench-ResNet, and Act-Bench-ViT were created by training convolutional, residual, and vision transformer architectures from scratch with 2,913 systematically generated activation functions. Second, a characterization of the benchmark space was developed, leading to a new surrogate-based method for optimization. More specifically, the spectrum of the Fisher information matrix associated with the model's predictive distribution at initialization and the activation function's output distribution were found to be highly predictive of performance. Third, the surrogate was used to discover improved activation functions in several real-world tasks, with a surprising finding: a sigmoidal design that outperformed all other activation functions was discovered, challenging the status quo of always using rectifier nonlinearities in deep learning. Each of these steps is a contribution in its own right; together they serve as a practical and theoretical foundation for further research on activation function optimization.
AutoInit: Analytic Signal-Preserving Weight Initialization for Neural Networks
Garrett Bingham and Risto Miikkulainen
AAAI 2023
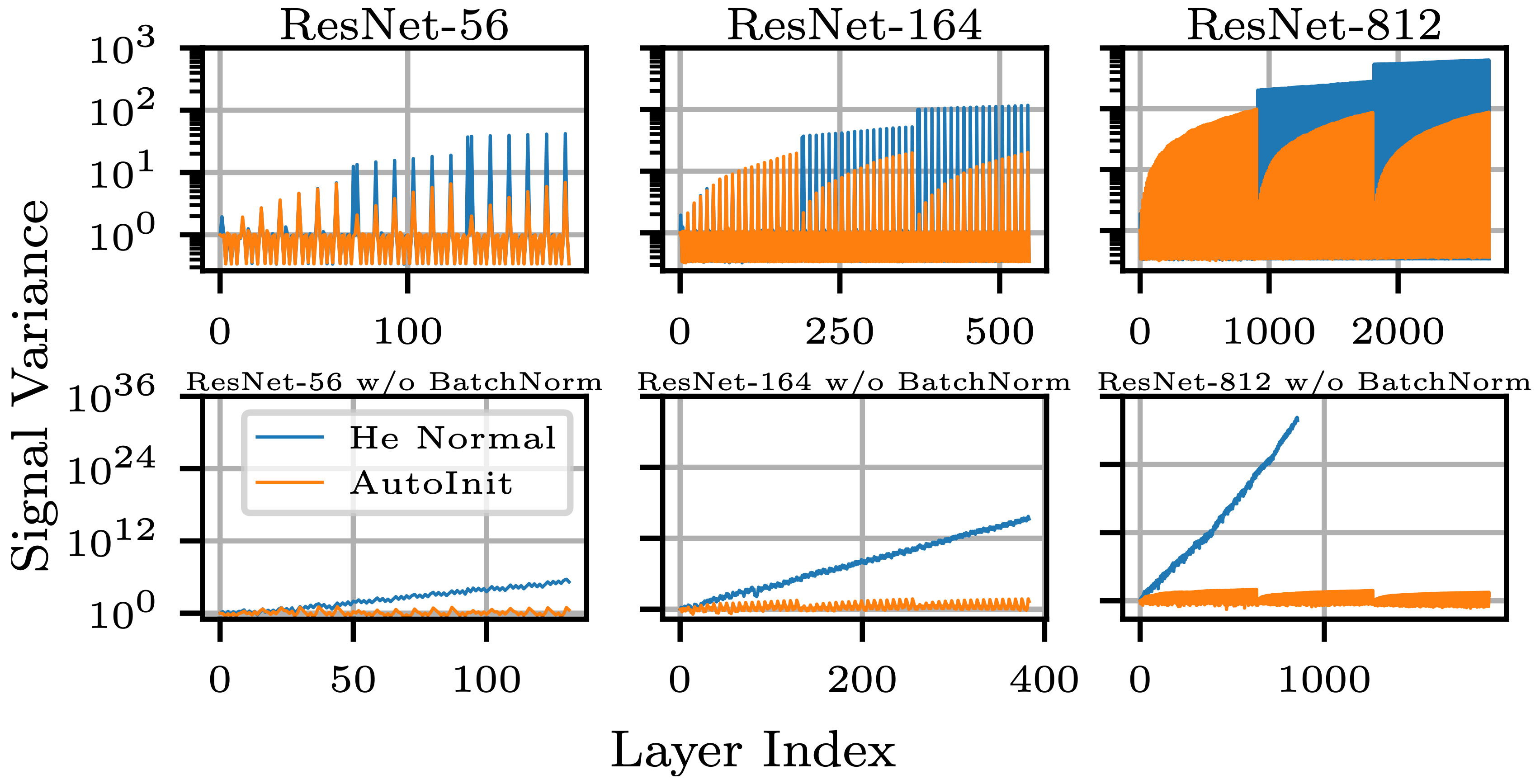
Neural networks require careful weight initialization to prevent signals from exploding or vanishing. Existing initialization schemes solve this problem in specific cases by assuming that the network has a certain activation function or topology. It is difficult to derive such weight initialization strategies, and modern architectures therefore often use these same initialization schemes even though their assumptions do not hold. This paper introduces AutoInit, a weight initialization algorithm that automatically adapts to different neural network architectures. By analytically tracking the mean and variance of signals as they propagate through the network, AutoInit appropriately scales the weights at each layer to avoid exploding or vanishing signals. Experiments demonstrate that AutoInit improves performance of convolutional, residual, and transformer networks across a range of activation function, dropout, weight decay, learning rate, and normalizer settings, and does so more reliably than data-dependent initialization methods. This flexibility allows AutoInit to initialize models for everything from small tabular tasks to large datasets such as ImageNet. Such generality turns out particularly useful in neural architecture search and in activation function discovery. In these settings, AutoInit initializes each candidate appropriately, making performance evaluations more accurate. AutoInit thus serves as an automatic configuration tool that makes design of new neural network architectures more robust. The AutoInit package provides a wrapper around TensorFlow models and is available at https://github.com/cognizant-ai-labs/autoinit.
Discovering Parametric Activation Functions
Garrett Bingham and Risto Miikkulainen
Neural Networks
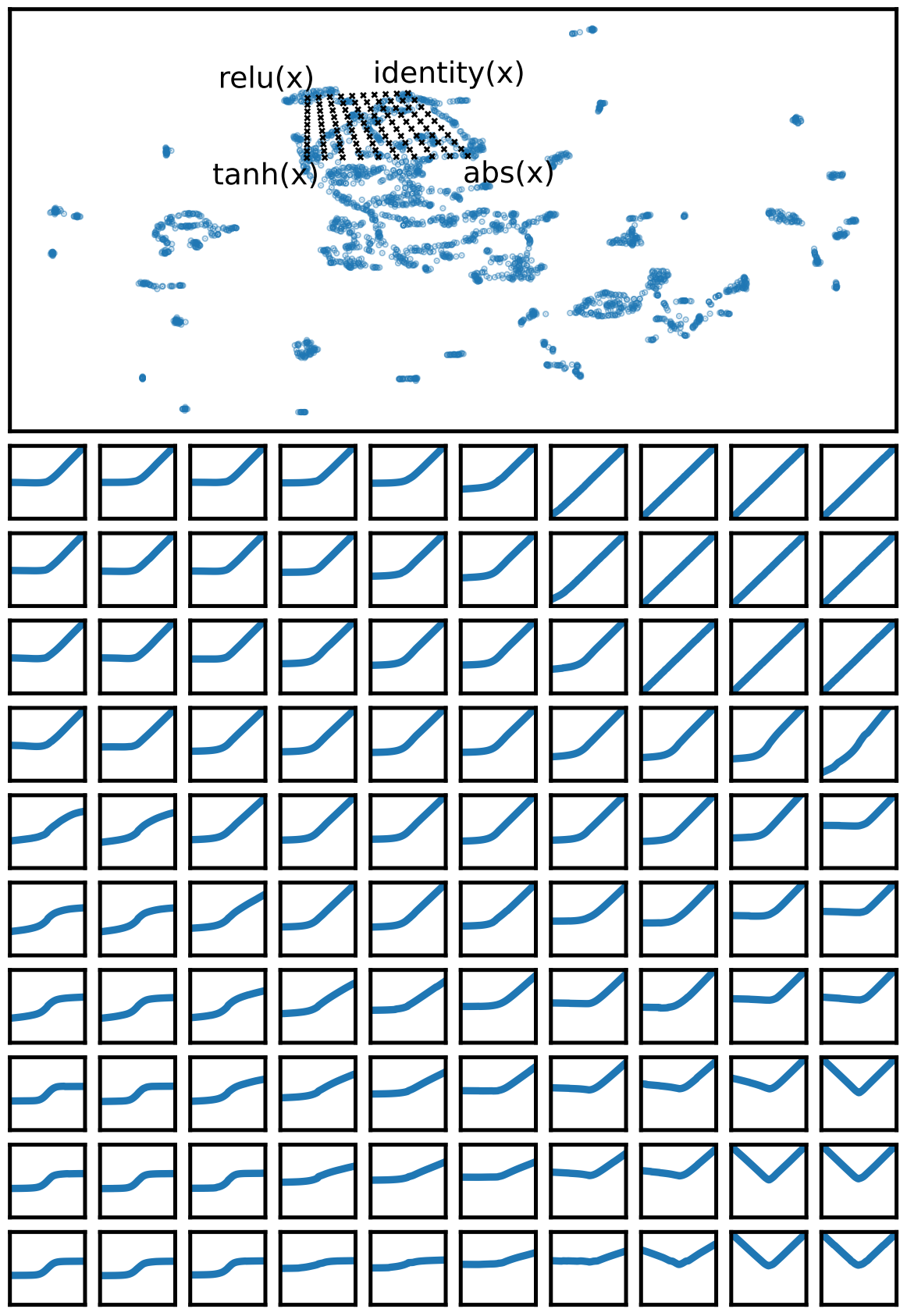
Recent studies have shown that the choice of activation function can significantly affect the performance of deep learning networks. However, the benefits of novel activation functions have been inconsistent and task dependent, and therefore the rectified linear unit (ReLU) is still the most commonly used. This paper proposes a technique for customizing activation functions automatically, resulting in reliable improvements in performance. Evolutionary search is used to discover the general form of the function, and gradient descent to optimize its parameters for different parts of the network and over the learning process. Experiments with four different neural network architectures on the CIFAR-10 and CIFAR-100 image classification datasets show that this approach is effective. It discovers both general activation functions and specialized functions for different architectures, consistently improving accuracy over ReLU and other activation functions by significant margins. The approach can therefore be used as an automated optimization step in applying deep learning to new tasks.
Evolutionary Optimization of Deep Learning Activation Functions
Garrett Bingham*, William Macke*, and Risto Miikkulainen
GECCO 2020

The choice of activation function can have a large effect on the performance of a neural network. While there have been some attempts to hand-engineer novel activation functions, the Rectified Linear Unit (ReLU) remains the most commonly-used in practice. This paper shows that evolutionary algorithms can discover novel activation functions that outperform ReLU. A tree-based search space of candidate activation functions is defined and explored with mutation, crossover, and exhaustive search. Experiments on training wide residual networks on the CIFAR-10 and CIFAR-100 image datasets show that this approach is effective. Replacing ReLU with evolved activation functions results in statistically significant increases in network accuracy. Optimal performance is achieved when evolution is allowed to customize activation functions to a particular task; however, these novel activation functions are shown to generalize, achieving high performance across tasks. Evolutionary optimization of activation functions is therefore a promising new dimension of metalearning in neural networks.
Improving Low-Resource Cross-lingual Document Retrieval by Reranking with Deep Bilingual Representations
Rui Zhang, Caitlin Westerfield, Sungrok Shim, Garrett Bingham, Alexander Fabbri, William Hu, Neha Verma, Dragomir Radev
ACL 2019
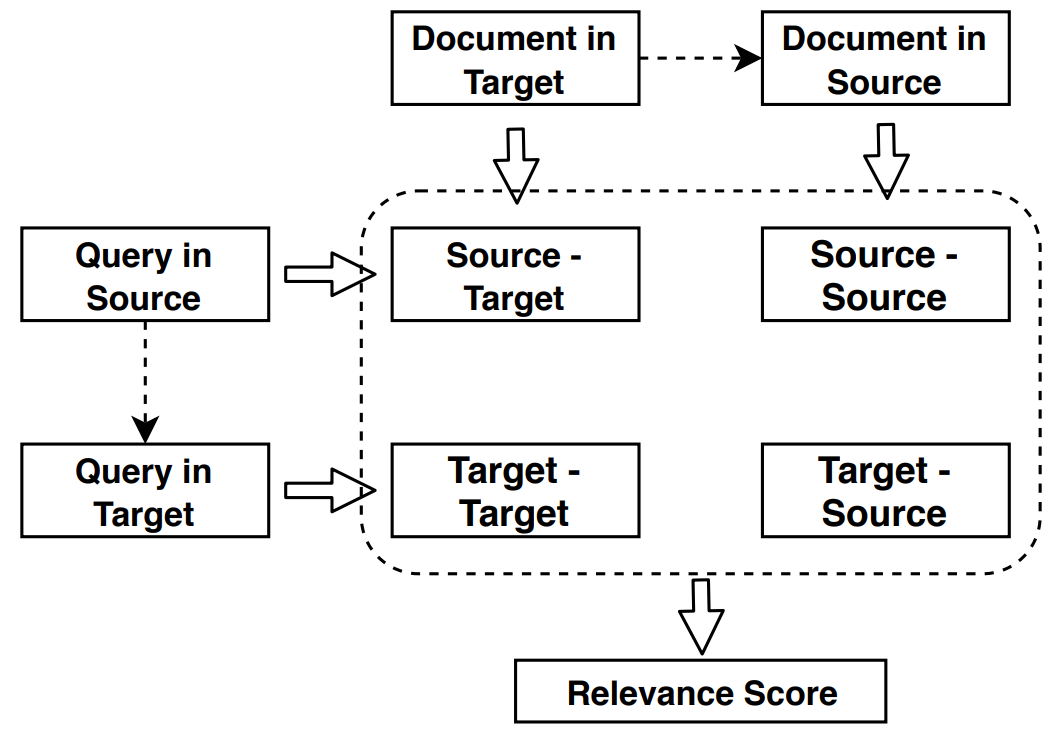
Low-resource cross-lingual document retrieval performance is improved with deep bilingual query-document representations. Experimental results on the MATERIAL dataset show that our model outperforms the competitive translation-based baselines on English-Swahili, English-Tagalog, and English-Somali cross-lingual information retrieval tasks.
Part of Speech Tagging with Neural Architecture Search
Garrett Bingham
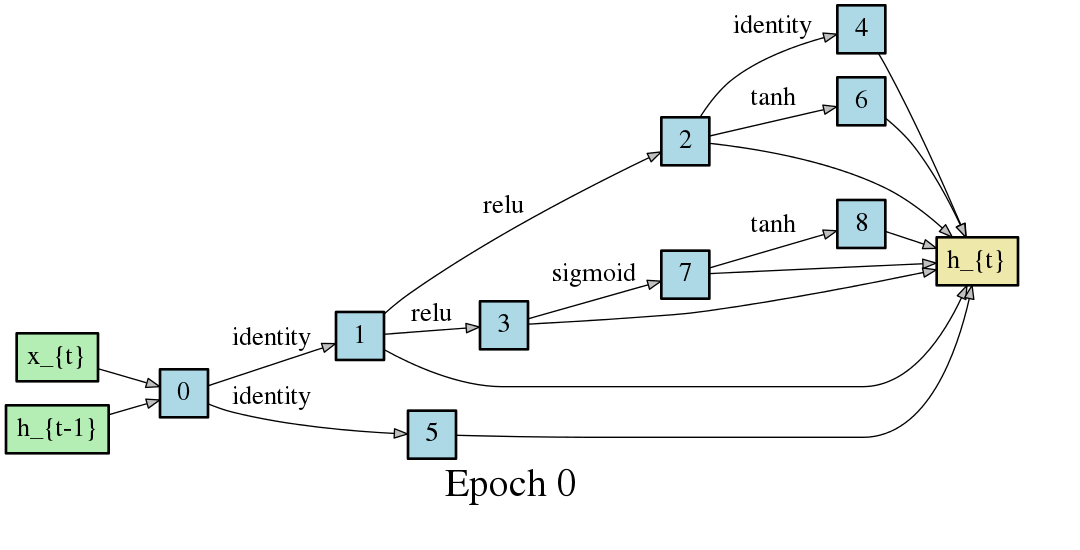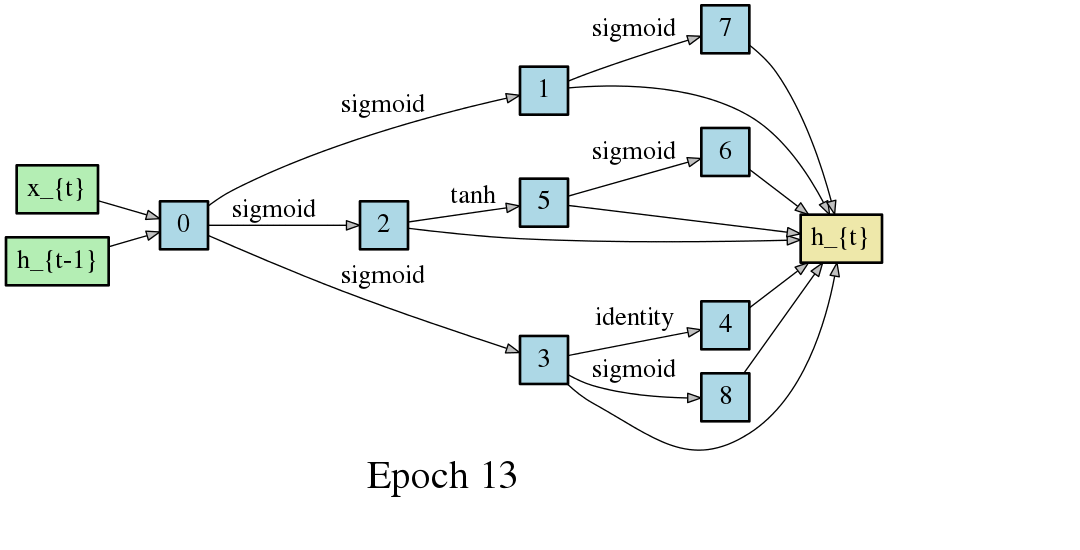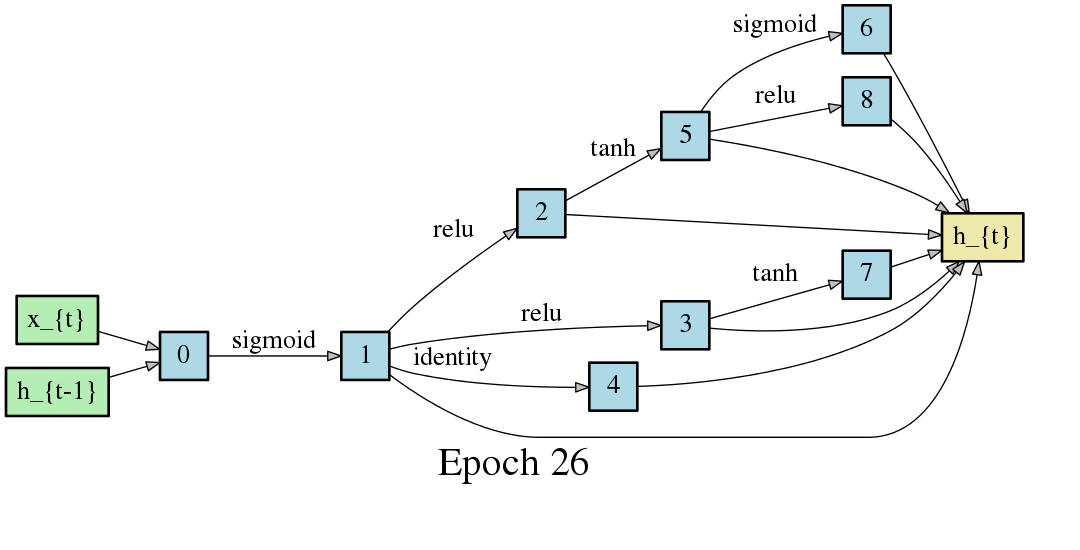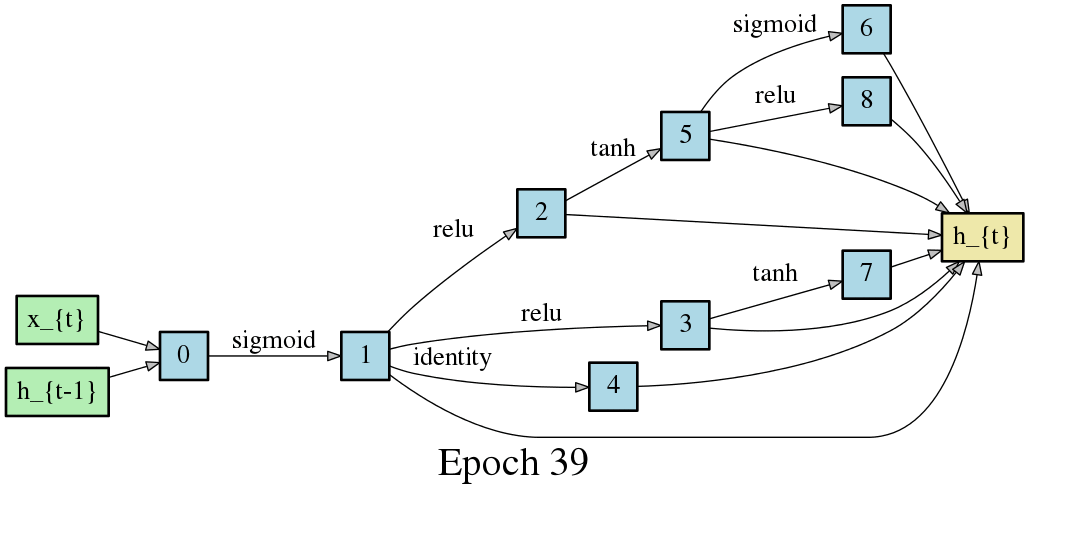
An automatically discovered bidirectional recurrent architecture nearly matches state-of-the-art accuracy for part of speech tagging across 60 treebanks.
Image credit: https://github.com/quark0/darts
Ineffectiveness of Gradient-based Neural Architecture Search
Garrett Bingham
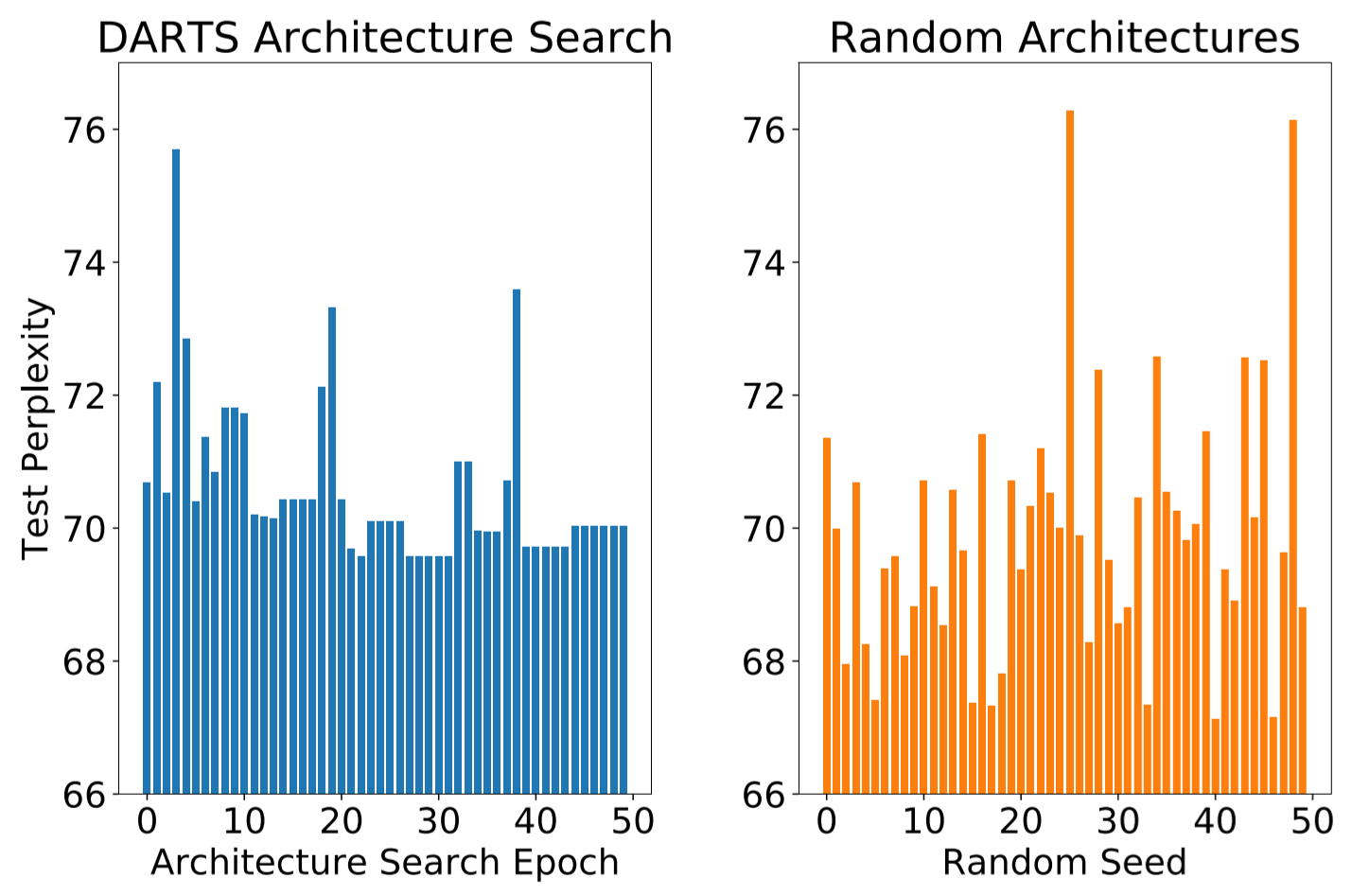
Most neural architecture search approaches utilize reinforcement learning or neuroevolutionary methods. Architecture optimization by gradient descent has been considered as a possible alternative. However, by training language models on Penn treebank, we demonstrate that gradient descent explores the search space ineffectively, and find that randomly initialized architectures are often able to outperform those discovered after extensive searching. We argue that gradient descent simply serves as a proxy for arbitrarily modifying the architecture, and show that gradient descent does not discover more capable architectures with each iteration of architecture search.
Preliminary Studies on a Large Face Database
Benjamin Yip, Garrett Bingham, Katherine Kempfert, Jonathan Fabish, Troy Kling, Cuixian Chen, and Yishi Wang
2018 IEEE International Conference on Big Data

I discovered thousands of gender, race, and birthdate inconsistencies in the MORPH-II face image dataset that previously published research had missed. In this paper we discuss our strategy to fix these errors and release these corrections in the hope that future research utilizing MORPH-II will be more accurate.
Random Subspace Two-dimensional LDA for Face Recognition
Garrett Bingham

Random Subspace Two-dimensional LDA (RS-2DLDA) improves upon a 2D generalization of LDA in which the input data is left in matrix form instead of being vectorized. RS-2DLDA builds an ensemble of classifiers by performing k-nearest neighbor classification in subspaces defined by random selections of the feature vectors learned during training. This gives high accuracy and prevents overfitting. Applied to face recognition, RS-2DLDA outperformed similar approaches on the MORPH-II and ORL datasets.
News

I joined Google DeepMind as a research scientist.

My research on neural network weight initialization was featured in the UT Austin Computer Science Department newsletter.

I developed key AutoML approaches to activation function design and automatic weight initialization working with the Evolutionary AI research team at Cognizant.

Our research on evolving activation functions was featured in the UT Austin Computer Science Department newsletter.

I obtained my Ph.D. in Computer Science from The University of Texas at Austin. I was supervised by Risto Miikkulainen.
In Amazon's Robotics AI group I developed an automated and parallelized solution for a video classification workflow.

I graduated cum laude from Yale University with a B.S. in Computer Science & Mathematics.
In the Language, Information, and Learning at Yale (LILY) Lab, I worked on cross-lingual information retrieval for the IARPA MATERIAL Program under the supervision of Prof. Dragomir Radev.

At Reservoir Labs, I used a polyhedral compiler to speed up neural network computations by improving a tool called R-Stream.TF. I was supervised by Dr. Benoit Meister.

I studied computer science at the Aquincum Institute of Technology in Budapest, Hungary.

Supervised by Dr. Cuixian Chen and Dr. Yishi Wang at UNC Wilmington, I developed a new algorithm for face recognition called RS-2DLDA. and delivered an oral presentation at the NES Mathematical Association of America Meeting hosted by Sacred Heart University.